For over two decades, SEO meant one thing: rank on Google. But 2025 marked a turning point. AI-powered tools like ChatGPT, Perplexity, and Claude now intercept millions of queries before they ever reach a traditional search results page. According to Cloudflare’s 2025 Radar Year in Review, AI user-action crawling – bots fetching live pages to answer real user queries – grew more than 15x in a single year. The old playbook of meta tags, backlinks, and keyword density is no longer sufficient on its own. You also need to speak the language of machines that read, reason, and recommend. Enter: llms.txt file.
By the Numbers: Google search traffic to publishers dropped 33% between November 2024 and November 2025. Meanwhile, zero-click AI answers are accelerating that decline. Your content strategy needs to account for the engines that now intercept that traffic.
WHAT IS LLMS.TXT?
An llms.txt file is a plain-text file placed at the root of your domain — for example, wordpattern.org/llms.txt — that gives AI crawlers a structured summary of who you are, what your site covers, and which pages matter most. Think of it as a robots.txt, but written specifically for large language models rather than traditional search bots.
While robots.txt says “here’s what you’re allowed to index,” llms.txt says “here’s what you should pay attention to.” It provides context, priorities, and permissions — a roadmap rather than a fence.
Here’s how the three files compare:
File | Audience | Primary Purpose | Standardised?
robots.txt | Google, Bing, etc. | Allow / block indexing by path | Yes (RFC)
sitemap.xml | Search engine crawlers | Enumerate all indexable pages | Yes
llms.txt | ChatGPT, Perplexity, Claude, Gemini | Summarise site, prioritise content, set AI usage rules | Unofficial (proposed 2024)
DOES LLMS.TXT ACTUALLY WORK?
This is the question every SEO professional is asking — and the honest answer is: it’s complicated.
Multiple studies have examined whether having an llms.txt file correlates with more AI citations. A study of 2,500 websites by Generix Marketing tested prompts across Perplexity, ChatGPT, and Claude and found no statistically significant uplift in citations attributable to the file alone. An analysis of 300,000 domains by SE Ranking similarly found no direct correlation between llms.txt adoption and AI citation frequency.
On top of that, server log audits show that major LLM crawlers — GPTBot, ClaudeBot, PerplexityBot — don’t currently request /llms.txt unprompted in most cases. Google has stated it has no plans to support the format.
Honest Take: There is currently no hard evidence that llms.txt directly boosts AI citations or rankings. The spec remains unofficial, and no major AI lab has formally committed to honouring it during inference. That said, implementation cost is near-zero — and early adoption of web standards has historically paid dividends.
Still, the SEO community’s growing consensus is that llms.txt is worth implementing for three reasons:
1. Future-proofing. The standard is evolving rapidly. Adoption among SaaS companies (Slack, Notion, Shopify, Dropbox) is growing 500%+ year-over-year. Getting ahead of the curve costs little.
2. Human-in-the-loop use cases. When users paste your URL directly into ChatGPT or Claude, a clean llms.txt helps the AI quickly understand your site’s structure and deliver accurate answers.
3. Content clarity. Writing an llms.txt forces you to articulate your site’s purpose and content hierarchy — a useful exercise regardless of AI uptake.
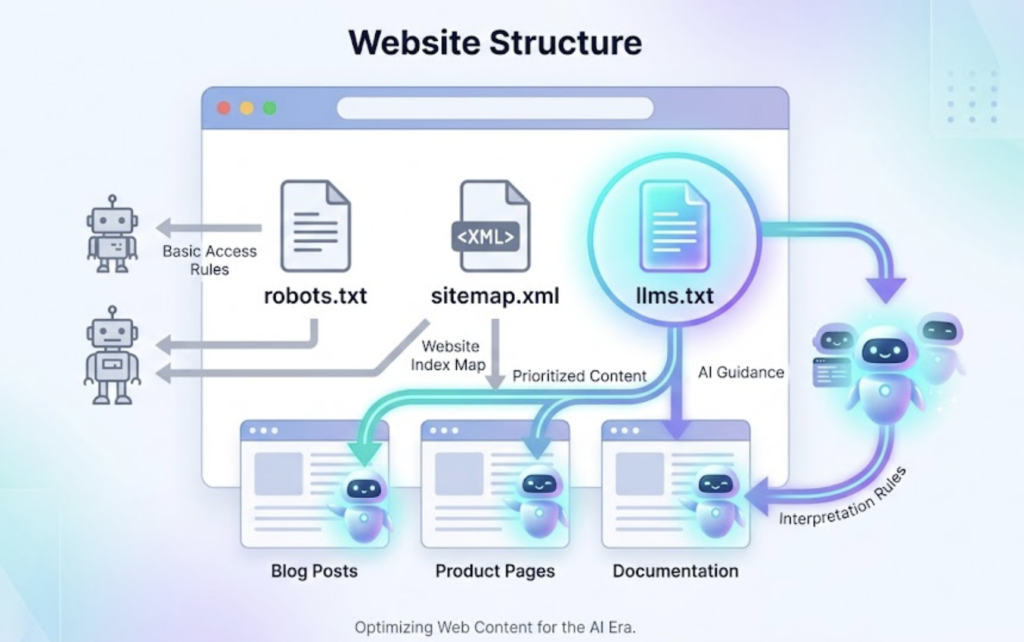
ANATOMY OF AN LLMS.TXT FILE
There is no single enforced schema, but the community-standard format uses Markdown-style syntax. Here’s what a well-structured file looks like for a site like WordPattern:
—
# WordPattern
> WordPattern monitors Google Search Console to detect content decay in real-time,
> identifies outdated sections, and generates AI-powered refreshes to recover organic
> traffic. Built for SEO teams managing large content libraries.
## Key Pages
– [Home](https://wordpattern.org/): Product overview and core value proposition
– [How It Works](https://wordpattern.org/how-it-works): Breakdown of the decay detection engine
– [Pricing](https://wordpattern.org/pricing): Plans and feature comparison
– [Blog](https://wordpattern.org/blog): SEO guides, AI search strategy, GEO tactics
## Documentation
– [API Docs](https://wordpattern.org/docs/api): Integration reference for developers
– [GSC Integration Guide](https://wordpattern.org/docs/gsc): How to connect Search Console
– [Content Refresh Workflow](https://wordpattern.org/docs/refresh): Step-by-step usage guide
## Content Topics
– [Content Decay](https://wordpattern.org/blog/content-decay): What it is and how to stop it
– [GEO Strategy](https://wordpattern.org/blog/geo): Generative Engine Optimisation tactics
– [AI SEO Guide](https://wordpattern.org/blog/ai-seo): Getting cited by ChatGPT and Perplexity
## Optional: Full Content Index
Optional: https://wordpattern.org/llms-full.txt
—
STEP-BY-STEP: BUILDING YOUR LLMS.TXT
Step 1: Write a One-Paragraph Site Description
Open with a >-prefixed blockquote that clearly explains what your site does, who it’s for, and what type of content it contains. Aim for 2–4 sentences. This is the most important section — it’s the first thing an AI reads.
Step 2: List Your Highest-Value Pages
Under a “## Key Pages” heading, add bullet-point links to your most important URLs — homepage, product pages, pricing, and your cornerstone content. Keep annotations concise: one sentence max per link.
Step 3: Add Documentation and Topical Sections
Group related content into themed sections using “## Section Name” headers. Aim for 4–8 links per section. The goal is a prioritised map, not an exhaustive catalogue — that’s what llms-full.txt is for.
Step 4: Optionally Create an llms-full.txt
For large sites, create a companion llms-full.txt that includes every page. Reference it at the bottom of your main file under an “Optional:” directive. Be aware: publishing a full content dump means competitors and AI crawlers can easily inventory your entire site — weigh that trade-off.
Step 5: Place the File at Your Domain Root
Upload to yourdomain.com/llms.txt. Serve with Content-Type: text/plain; charset=utf-8. Most static site hosts, WordPress installs, and CDNs can serve this without any special configuration.
Step 6: Track and Measure Over Time
Instrument your /llms.txt endpoint in your analytics. Filter by User-Agent to see if GPTBot, ClaudeBot, or PerplexityBot are fetching it. Use the SEO intelligence gathered from these logs to understand which AI agents are most interested in your content. Monthly, manually test your target queries in ChatGPT, Perplexity, and Claude — note whether your site is cited and where.
LLMS.TXT AND WORDPATTERN: A NATURAL PAIRING
WordPattern already does the hard work of identifying which pages on your site are gaining or losing organic momentum. That same intelligence maps directly to what your llms.txt should highlight. Pages that are recovering from content decay — freshly refreshed, semantically enriched, and re-ranked — deserve priority placement in your AI roadmap file.
Think of it as a two-layer strategy: WordPattern keeps your content sharp for traditional search; llms.txt signals your best work to the AI engines that are increasingly shaping what users find. Together, they cover both the present and the future of organic discovery.
💡 Pro Tip: After every major content refresh through WordPattern, update your llms.txt to reflect the refreshed URL. This keeps your AI roadmap aligned with your best-performing, most up-to-date content — the exact pages you want AI engines citing.
BROADER AI SEO: WHAT ACTUALLY MOVES THE NEEDLE?
Even the most honest proponents of llms.txt will tell you it’s one small piece of a larger puzzle. The factors that consistently correlate with AI citations are the same ones that have driven great SEO for years — with a few new twists:
Topical authority. AI engines favour sources that comprehensively cover a subject area. A single well-optimised post matters less than a cluster of interlinked, expert-level content around a topic.
Content freshness. Perplexity, in particular, retrieves from the live web. Outdated content — even with a good backlink profile — gets deprioritised in real-time retrieval scenarios. This is precisely the decay problem WordPattern was built to solve.
Structured, scannable writing. Use question-and-answer formatting, clear H2/H3 hierarchies, and specific factual claims. AI extractors parse headers and paragraphs, not dense walls of text. Many marketers also combine these optimisation strategies with an SMM Panel to improve social visibility and amplify content reach across digital platforms.
Entity clarity. Name your brand, your product, your people, and your geography explicitly. LLMs use named entities as anchors when building citations.
Clean Markdown routes. Consider serving .md versions of key pages alongside your HTML. Content negotiation via Accept: text/markdown is standards-compliant and makes extraction dramatically easier for AI agents.
THE BOTTOM LINE
Is llms.txt a silver bullet? No. Will it double your Perplexity citations overnight? Almost certainly not. But in a discipline where early-mover advantage is real — and where the web is actively transitioning from keyword-based to meaning-based discovery — implementing a thoughtful, accurate llms.txt is one of the lowest-effort, highest-upside moves available to any site owner today.
The cost is 30 minutes. The potential payoff, as LLM crawlers formalise their support for the spec, is first-mover visibility in the AI search results that are replacing the blue links we’ve optimised for since the early 2000s.
Build the file. Keep it updated. And pair it with the content quality work that will always be the true engine of long-term discoverability — in any era of search.